


Our method starts from two concrete desiderata for inference-time steering:
- (D1) exploit low-noise timesteps—where rewards are trustworthy—to revise earlier, high-noise decisions;
- (D2) turn extra compute into better samples rather than merely more particles, yielding an anytime algorithm.
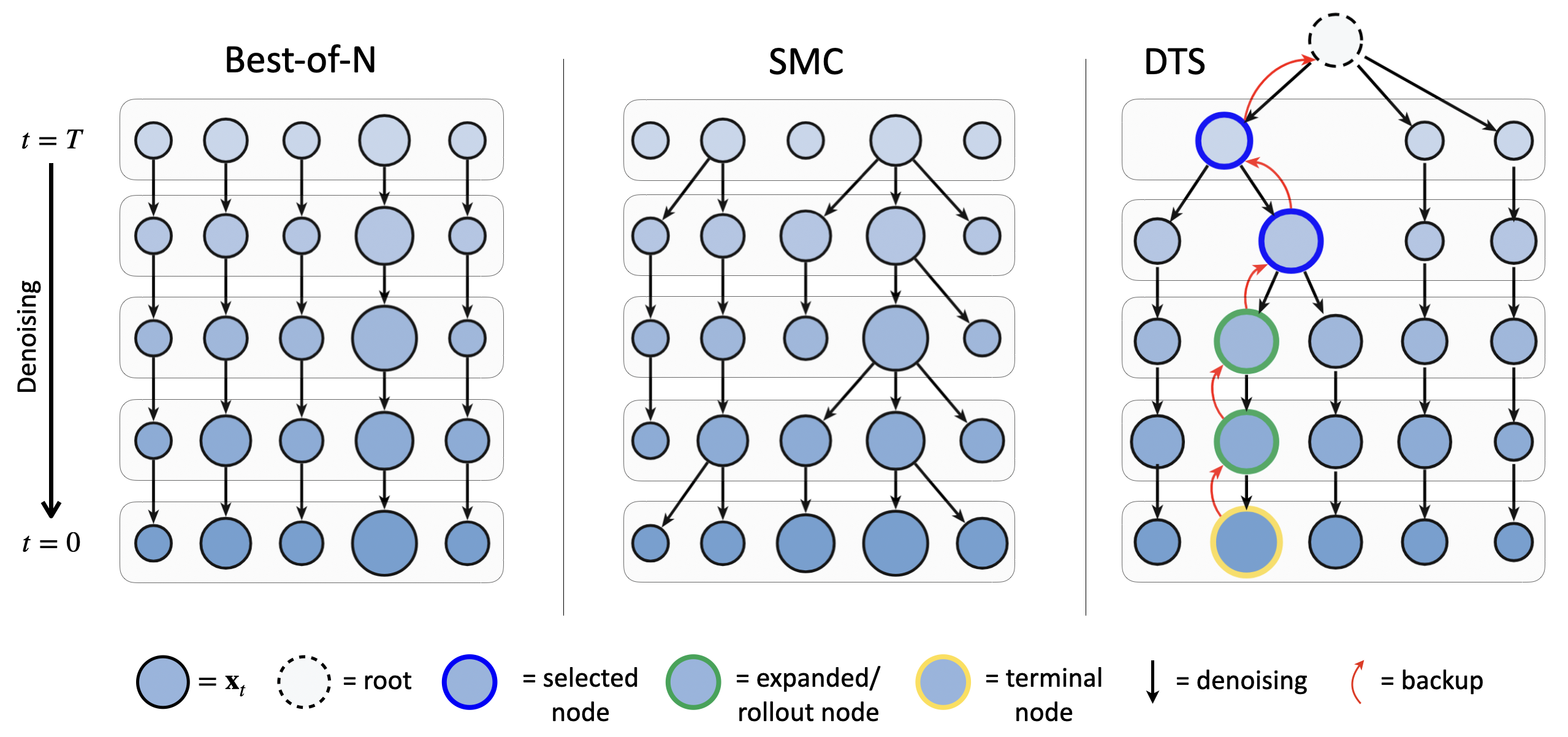
Reverse diffusion as a search tree
Because the learned reverse chain $p_\theta(x_{t-1} | x_t)$ is Markov with finite horizon $T$, we reinterpret the denoising process as a depth-$T$ tree in $\mathbb{R}^d$. A node at depth $t$ stores the noisy latent $x_t$, a running soft-value estimate $\hat{v}(x_t)$, and a visit count; each edge is a stochastic denoising step. This framing allows us to keep track of information across multiple denoising trajectories, including estimates of the soft value function, which helps with global credit assignment.
Diffusion Tree Sampling & Search
Tree traversal alternates selection → expansion → rollout → backup:
- Selection: Starting from the root, sample children according to a Boltzmann policy $\propto \exp(\lambda \hat{v}(\cdot))$.
- Expansion: If the selected node has fewer children than the maximum and $t > 0$, draw a new child from $x_{t-1} \sim p_\theta(\cdot | x_t)$.
- Rollout: From the newly created node, perform a rollout till $x_0$ using $p_\theta$; every intermediate state is appended to the tree.
- Backup: Evaluate terminal reward $r(x_0)$ and update value estimates along the path using the soft Bellman backup.
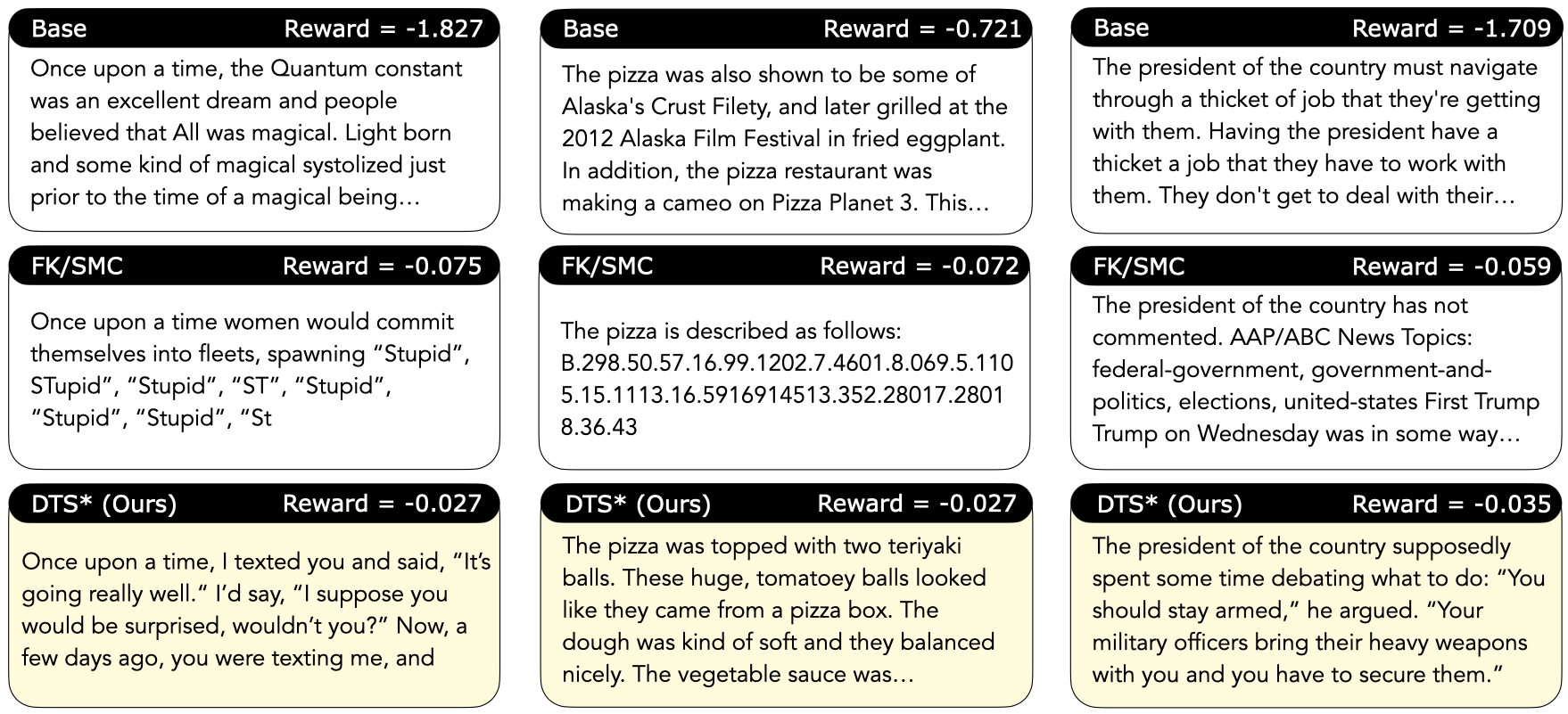
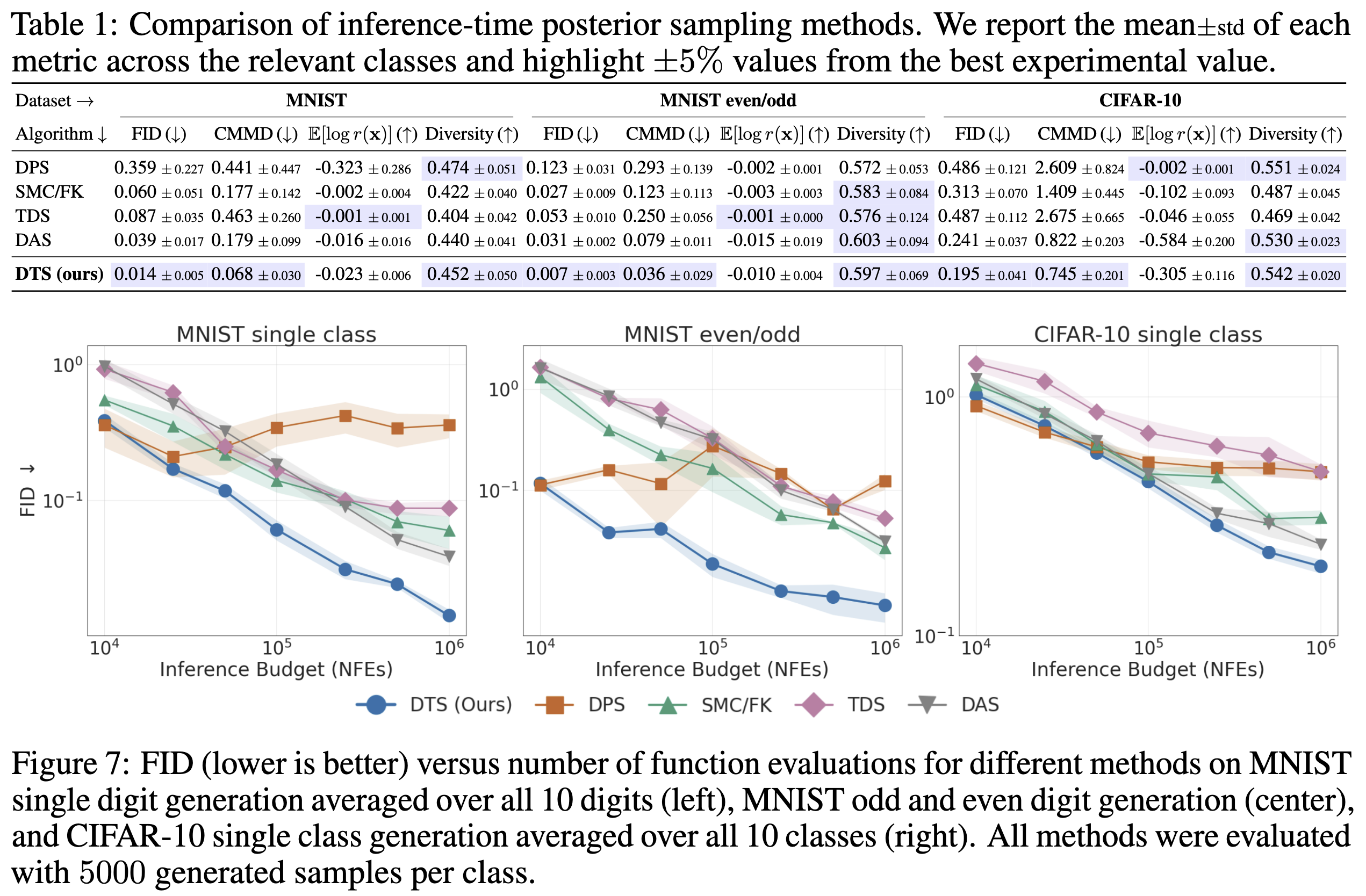
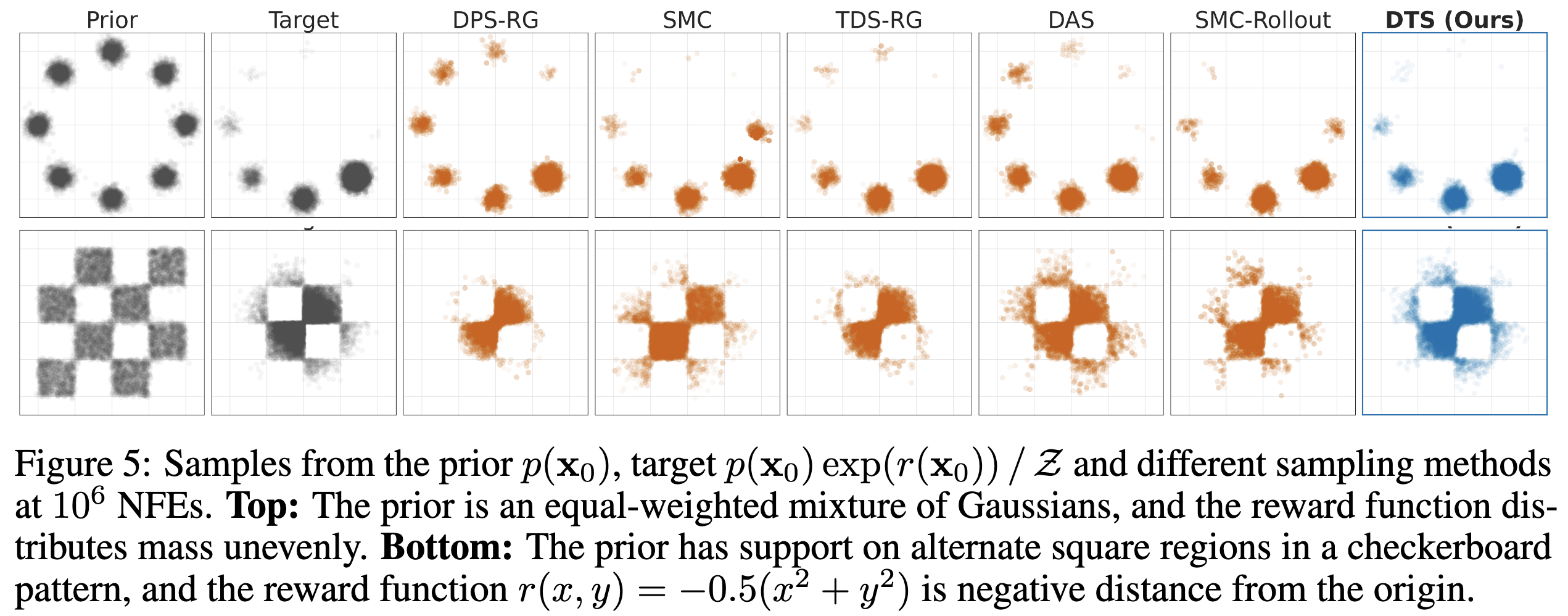
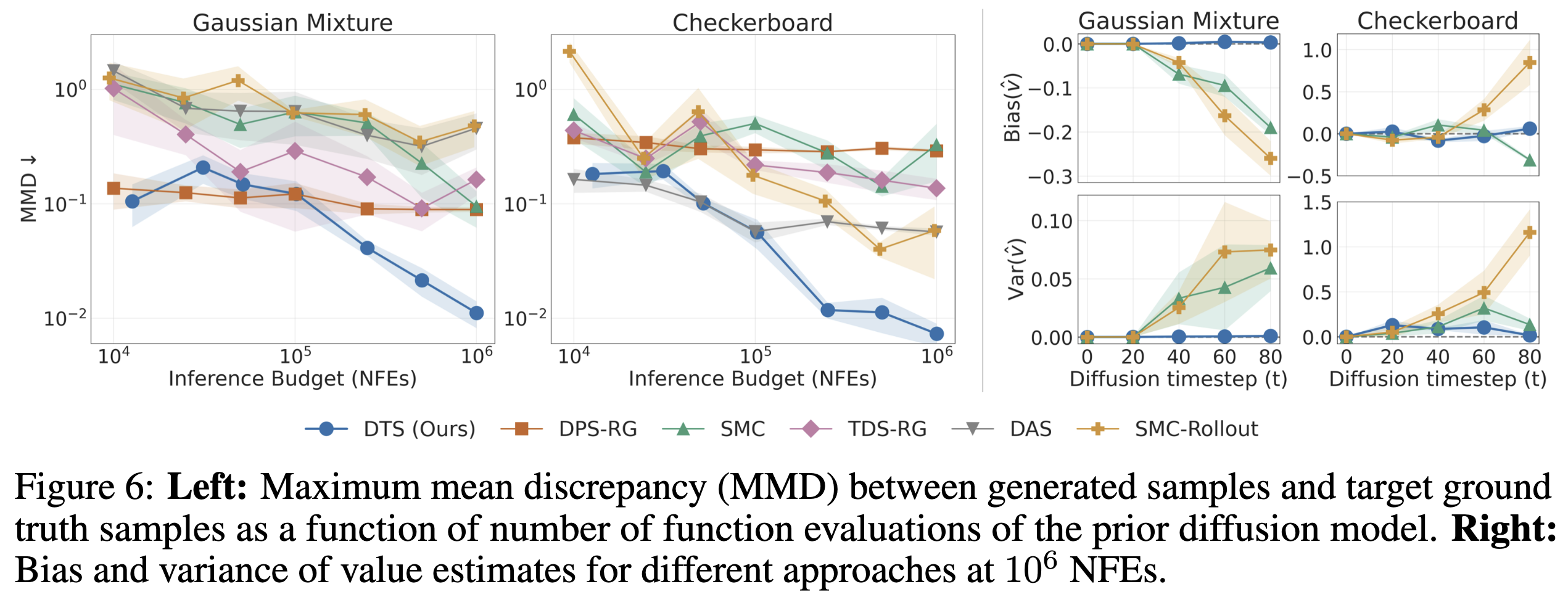
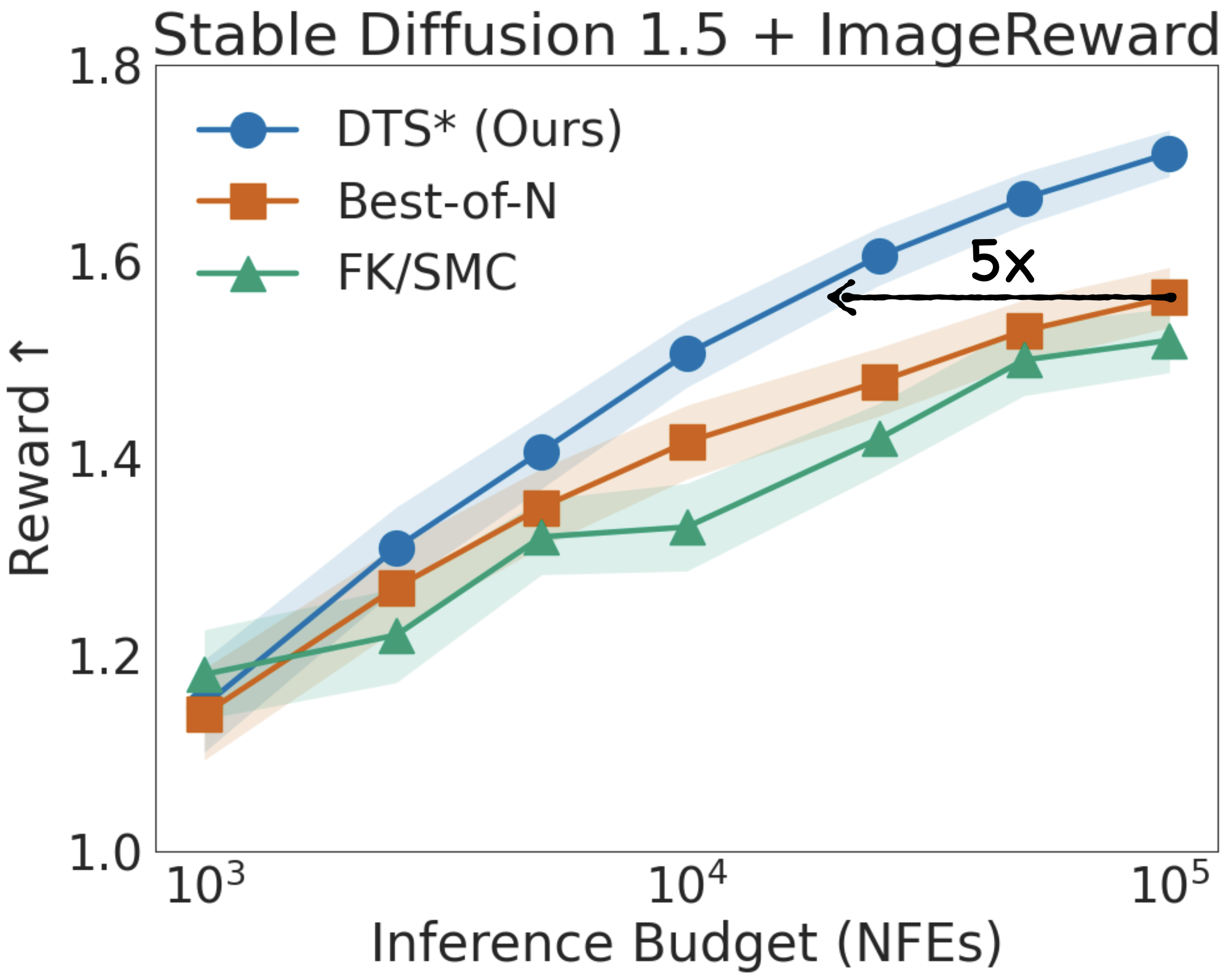
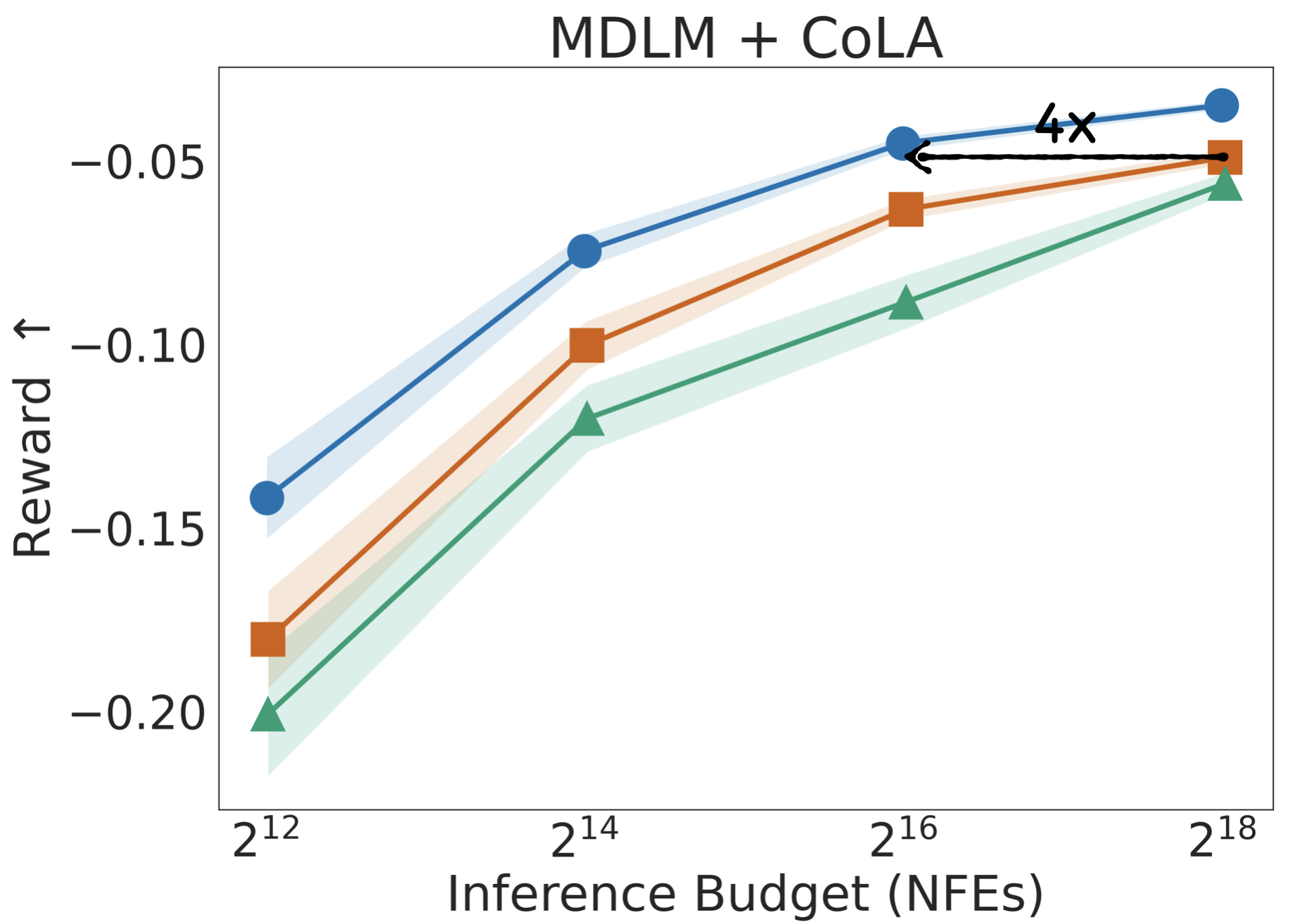
Repeating this loop yields Diffusion Tree Sampling (DTS), an anytime sampler whose empirical distribution provably converges to the target density $p_\theta(x) \exp(r(x))$. Switching the selection rule to greedy maximization produces Diffusion Tree Search (DTS$^\star$) to find high reward samples without over-optimization — no other code changes required.